
I work at Sea AI Lab  as a research scientist now, leading the audio team and doing some fundamental audio-related research. We are hiring researchers and engineers to work on TTS, music generation, speech translation and audio-driven talking face generation. If interested, feel free to email me at renyi@sea.com.
as a research scientist now, leading the audio team and doing some fundamental audio-related research. We are hiring researchers and engineers to work on TTS, music generation, speech translation and audio-driven talking face generation. If interested, feel free to email me at renyi@sea.com.
I graduated from Chu Kochen Honors College, Zhejiang University (浙江大学竺可桢学院) with a bachelor’s degree and from the Department of Computer Science and Technology, Zhejiang University (浙江大学计算机科学与技术学院) with a master’s degree, advised by Zhao Zhou (赵洲). I also collaborate with Xu Tan (谭旭), Tao Qin (秦涛) and Tie-yan Liu (刘铁岩) from Microsoft Research Asia ![]() closely.
closely.
I won the Baidu Scholarship (10 candidates worldwide each year) and ByteDance Scholars Program (10 candidates worldwide each year) in 2020 and was selected as one of the top 100 AI Chinese new stars and AI Chinese New Star Outstanding Scholar (10 candidates worldwide each year).
My research interest includes speech synthesis, neural machine translation and automatic music generation. I have published more than 20 papers 
To promote the communication among the Chinese ML & NLP community, we (along with other 11 young scholars worldwide) founded the MLNLP community in 2021. I am honored to be one of the chairs of the MLNLP committee.
🔥 News
- 2022.05: I join Sea AI Lab as the audio team leader. We are hiring researchers and engineers!
- 2022.04: Three papers are accepted by IJCAI 2022:
- SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech, Zhenhui Ye, Zhou Zhao, Yi Ren, Fei Wu
- EditSinger: Zero-Shot Text-Based Singing Voice Editing System with Diverse Prosody Modeling, Lichao Zhang, Zhou Zhao, Yi Ren, Liqun Deng
- FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis, Rongjie Huang, Max W. Y. Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, Zhou Zhao
- 2022.03: We release NeuralSVB, the code of our ACL 2022 work (singing voice beautifying). 🚧 ⛏️ 🛠️ 👷
- 2022.02: I release a modern and responsive academic personal homepage template. Welcome to STAR and FORK!
- 2022.02: 🎉🎉 Two papers are accepted by ACL 2022:
- Revisiting Over-Smoothness in Text to Speech, Yi Ren, Xu Tan, Tao Qin, Zhou Zhao, Tie-Yan Liu
- Learning the Beauty in Songs: Neural Singing Voice Beautifier, Jinglin Liu, Chengxi Li, Yi Ren, Zhiying Zhu, Zhou Zhao |
- 2022.02: 🎉🎉 My google scholar citations have exceeded 1000!
- 2022.02: We public a Non-Autoregressive Text-to-Speech (NAR-TTS) framework NATSpeech
, including official PyTorch implementation of PortaSpeech (NeurIPS 2021) and DiffSpeech (AAAI 2022). 🎉🎉 It was shown on the Github Daily Trending List on 19 Feb 2022!

📝 Publications
🎙 Speech Synthesis
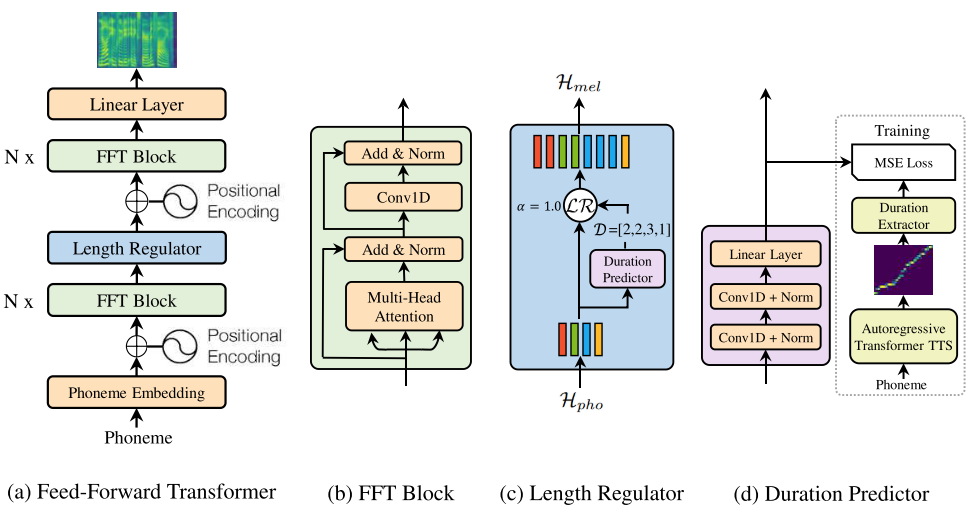
FastSpeech: Fast, Robust and Controllable Text to Speech
Yi Ren, Yangjun Ruan, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
- FastSpeech is the first fully parallel end-to-end speech synthesis model.
- Academic Impact: This work is included by many famous speech synthesis open-source projects, such as ESPNet
. Our work are promoted by more than 20 media and forums, such as 机器之心、InfoQ.
- Industry Impact: FastSpeech has been deployed in Microsoft Azure TTS service and supports 49 more languages with state-of-the-art AI quality. It was also shown as a text-to-speech system acceleration example in NVIDIA GTC2020.
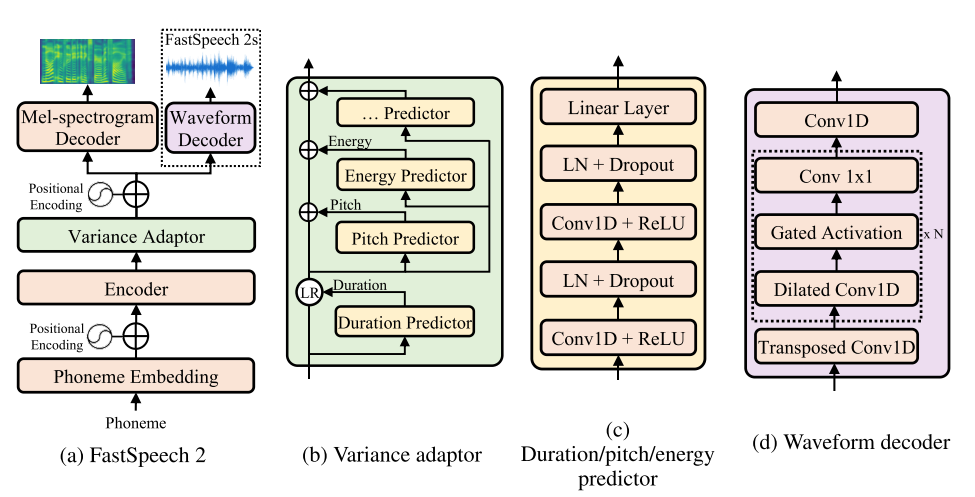
FastSpeech 2: Fast and High-Quality End-to-End Text to Speech
Yi Ren, Chenxu Hu, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu
- This work is included by many famous speech synthesis open-source projects, such as PaddlePaddle/Parakeet
, ESPNet
.
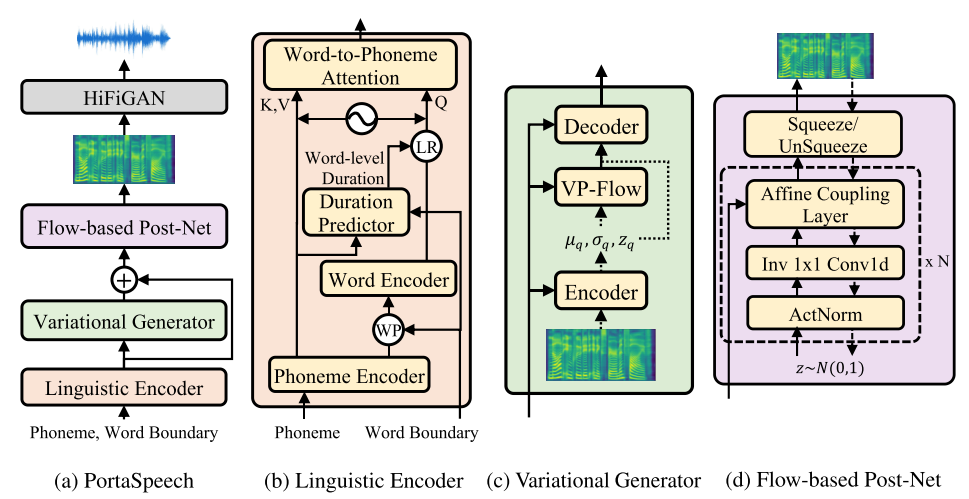
PortaSpeech: Portable and High-Quality Generative Text-to-Speech
Yi Ren, Jinglin Liu, Zhou Zhao
Project | 
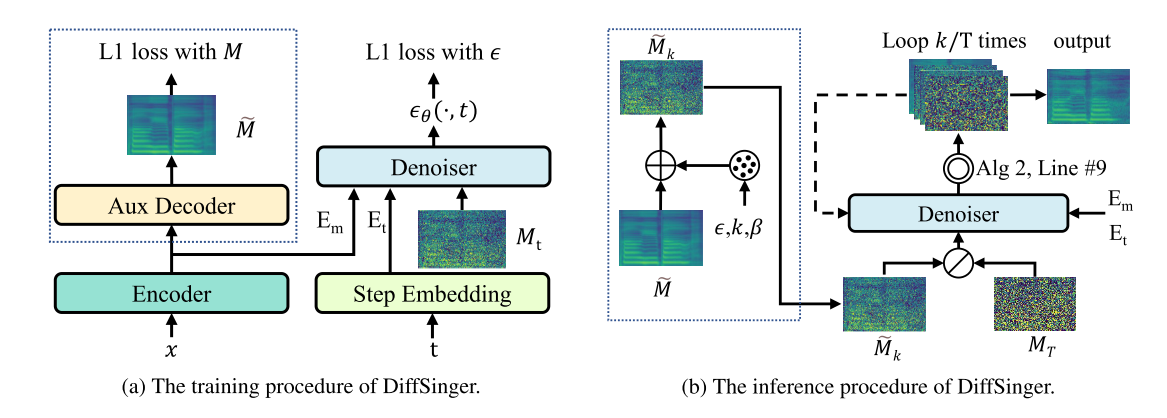
DiffSinger: Singing Voice Synthesis via Shallow Diffusion Mechanism
Jinglin Liu, Chengxi Li, Yi Ren, Feiyang Chen, Zhou Zhao
Project | 

- SyntaSpeech: Syntax-Aware Generative Adversarial Text-to-Speech, Zhenhui Ye, Zhou Zhao, Yi Ren, Fei Wu, IJCAI 2022
- EditSinger: Zero-Shot Text-Based Singing Voice Editing System with Diverse Prosody Modeling, Lichao Zhang, Zhou Zhao, Yi Ren, Liqun Deng, IJCAI 2022 (Oral)
- FastDiff: A Fast Conditional Diffusion Model for High-Quality Speech Synthesis, Rongjie Huang, Max W. Y. Lam, Jun Wang, Dan Su, Dong Yu, Yi Ren, Zhou Zhao, IJCAI 2022 (Oral)
- Revisiting Over-Smoothness in Text to Speech, Yi Ren, Xu Tan, Tao Qin, Zhou Zhao, Tie-Yan Liu, ACL 2022
- Learning the Beauty in Songs: Neural Singing Voice Beautifier, Jinglin Liu, Chengxi Li, Yi Ren, Zhiying Zhu, Zhou Zhao, ACL 2022 |
- ProsoSpeech: Enhancing Prosody With Quantized Vector Pre-training in Text-to-Speech, Yi Ren, Ming Lei, Zhiying Huang, Shiliang Zhang, Qian Chen, Zhijie Yan, Zhou Zhao, ICASSP 2022
- EMOVIE: A Mandarin Emotion Speech Dataset with a Simple Emotional Text-to-Speech Model, Chenye Cui, Yi Ren, Jinglin Liu, Feiyang Chen, Rongjie Huang, Ming Lei and Zhou Zhao, INTERSPEECH 2021
- WSRGlow: A Glow-based Waveform Generative Model for Audio Super-Resolution, Kexun Zhang, Yi Ren, Changliang Xu and Zhou Zhao, INTERSPEECH 2021 (best student paper award candidate)
- Denoising Text to Speech with Frame-Level Noise Modeling, Chen Zhang, Yi Ren, Xu Tan, Jinglin Liu, Kejun Zhang, Tao Qin, Sheng Zhao, Tie-Yan Liu, ICASSP 2021 | Project
- Multi-Singer: Fast Multi-Singer Singing Voice Vocoder With A Large-Scale Corpus, Rongjie Huang, Feiyang Chen, Yi Ren, Jinglin Liu, Chenye Cui, Zhou Zhao, ACM-MM 2021 (Oral)
- FedSpeech: Federated Text-to-Speech with Continual Learning, Ziyue Jiang, Yi Ren, Ming Lei and Zhou Zhao, IJCAI 2021
- DeepSinger: Singing Voice Synthesis with Data Mined From the Web, Yi Ren, Xu Tan, Tao Qin, Jian Luan, Zhou Zhao, Tie-Yan Liu, KDD 2020 | Project
- LRSpeech: Extremely Low-Resource Speech Synthesis and Recognition, Jin Xu, Xu Tan, Yi Ren, Tao Qin, Jian Li, Sheng Zhao, Tie-Yan Liu, KDD 2020 | Project
- MultiSpeech: Multi-Speaker Text to Speech with Transformer, Mingjian Chen, Xu Tan, Yi Ren, Jin Xu, Hao Sun, Sheng Zhao, Tao Qin, INTERSPEECH 2020 | Project
- Almost Unsupervised Text to Speech and Automatic Speech Recognition, Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, Zhou Zhao, Tie-Yan Liu, ICML 2019 (Oral) | Project
👄 Lip Generation/Understanding
- Parallel and High-Fidelity Text-to-Lip Generation, Jinglin Liu, Zhiying Zhu, Yi Ren, Wencan Huang, Baoxing Huai, Nicholas Yuan, Zhou Zhao, AAAI 2022 |
- Flow-based Unconstrained Lip to Speech Generation, Jinzheng He, Zhou Zhao, Yi Ren, Jinglin Liu, Baoxing Huai, Nicholas Yuan, AAAI 2022
- FastLR: Non-Autoregressive Lipreading Model with Integrate-and-Fire, Jinglin Liu, Yi Ren, Zhou Zhao, Chen Zhang, Baoxing Huai, Jing Yuan, ACM-MM 2020

📚 Machine Translation
- UWSpeech: Speech to Speech Translation for Unwritten Languages, Chen Zhang, Xu Tan, Yi Ren, Tao Qin, Kejun Zhang, Tie-Yan Liu, AAAI 2021 | Project
- Task-Level Curriculum Learning for Non-Autoregressive Neural Machine Translation, Jinglin Liu, Yi Ren, Xu Tan, Chen Zhang, Tao Qin, Zhou Zhao and Tie-Yan Liu, IJCAI 2020
- SimulSpeech: End-to-End Simultaneous Speech to Text Translation, Yi Ren, Jinglin Liu, Xu Tan, Chen Zhang, Qin Tao, Zhou Zhao, Tie-Yan Liu, ACL 2020
- A Study of Non-autoregressive Model for Sequence Generation, Yi Ren, Jinglin Liu, Xu Tan, Zhou Zhao, Sheng Zhao, Tie-Yan Liu, ACL 2020
- Multilingual Neural Machine Translation with Knowledge Distillation, Xu Tan, Yi Ren, Di He, Tao Qin, Zhou Zhao, Tie-Yan Liu, ICLR 2019
🎼 Music Generation
- SongMASS: Automatic Song Writing with Pre-training and Alignment Constraint, Zhonghao Sheng, Kaitao Song, Xu Tan, Yi Ren, Wei Ye, Shikun Zhang, Tao Qin, AAAI 2021
- PopMAG: Pop Music Accompaniment Generation, Yi Ren, Jinzheng He, Xu Tan, Tao Qin, Zhou Zhao, Tie-Yan Liu, ACM-MM 2020 (Oral) | Project
🧑🎨 Generative Model
- Pseudo Numerical Methods for Diffusion Models on Manifolds, Luping Liu, Yi Ren, Zhijie Lin, Zhou Zhao, ICLR 2022 |
|

🎖 Honors and Awards
- 2021.10 Tencent Scholarship (Top 1%)
- 2021.10 National Scholarship (Top 1%)
- 2020.12 Baidu Scholarship (10 students in the world each year)
- 2020.12 AI Chinese new stars (100 worldwide each year)
- 2020.12 AI Chinese New Star Outstanding Scholar (10 candidates worldwide each year)
- 2020.12 ByteDance Scholars Program (10 students in China each year)
- 2020.10 Tianzhou Chen Scholarship (Top 1%)
- 2020.10 National Scholarship (Top 1%)
- 2015.10 National Scholarship (Undergraduate) (Top 1%)
📖 Educations
- 2019.06 - 2022.04 (now), Master, Zhejiang University, Hangzhou.
- 2015.09 - 2019.06, Undergraduate, Chu Kochen Honors College, Zhejiang Univeristy, Hangzhou.
- 2012.09 - 2015.06, Luqiao Middle School, Taizhou.
💬 Invited Talks
- 2022.02, Hosted MLNLP seminar | [Video]
- 2021.06, Audio & Speech Synthesis, Huawei internal talk
- 2021.03, Non-autoregressive Speech Synthesis, PaperWeekly & biendata | [video]
- 2020.12, Non-autoregressive Speech Synthesis, Huawei Noah’s Ark Lab internal talk
💻 Internships
- 2019.05 - 2020.02, EnjoyMusic, Hangzhou.
- 2019.02 - 2019.05, YiWise, Hangzhou.
- 2018.08 - 2019.02, MSRA, machine learning Group, Beijing.
- 2018.01 - 2018.06, NetEase, AI department, Hangzhou.
- 2017.08 - 2018.12, DashBase (acquired by Cisco), Hangzhou.